A Simple Tutorial on the LibRec
Overview, Algorithms, How-to-Run, Configuration, Development
LibRec is a GPL-licensed Java library for recommender systems (version 1.7 or higher required). It implements a suite of state-of-the-art recommendation algorithms. It consists of three major components: interfaces, data structures and recommendation algorithms, as illustrated in Figure 1. Interfaces defines a number of abstract recommenders to be extended or implemented by specific algorithms, while data dtructures provides functionality to store and read data efficiently, and frequently used by a series of recommendation algorithms.
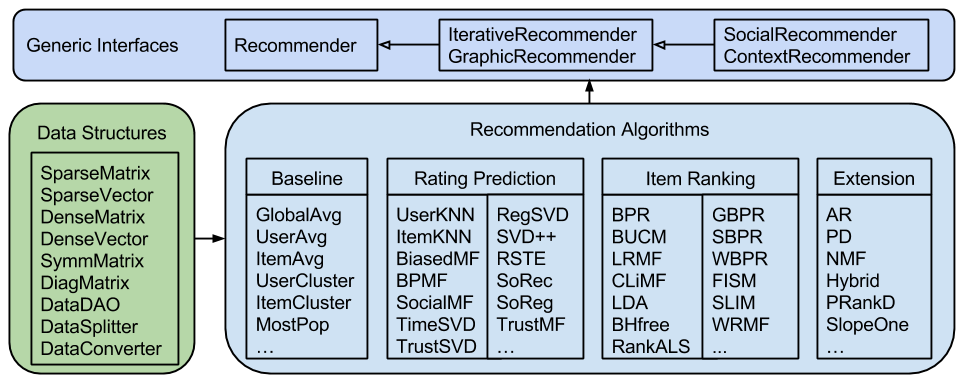
Figure 1. The Class Structure of the LibRec Library
- Cross-platform: as a Java software, LibRec can be easily deployed and executed in any platforms, including MS Windows, Linux and Mac OS.
- Fast execution: LibRec runs much faster than other libraries (see a detailed comparison on various datasets).
- Easy configuration: LibRec configs recommenders using a configuration file: librec.conf (see how to config a recommender).
- Easy expansion: LibRec provides a set of recommendation interfaces for easy exapansion (see how to implement a new recommender).
- Recommender: a general inferface for algorithms that are not based on iterative learning or social information, such as UserKNN, ItemKNN, SlopeOne, etc.
- IterativeRecommender: an interface for algorithms that are based on iterative learning methods, such as matrix factorization based approaches, RegSVD, SVD++, PMF, etc.
- GraphicRecommender: an interface for algorithms that are based on probabilistic graphic models, such as LDA, URP, etc.
- SocialRecommender: an interface for algorithms that adopt social information, such as SocialMF, TrustMF, TrustSVD, etc.
- ContextRecommender: an interface for algorithms that make use of side contextual information, such as TimeSVD++, etc.
Algorithms
| Rating Prediction | References |
|---|---|
| BiasedMF | Koren, Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model, KDD 2008. |
| BPMF | Salakhutdinov and Mnih, Bayesian Probabilistic Matrix Factorization using Markov Chain Monte Carlo, ICML 2008. |
| GPLSA | Thomas Hofmann, Collaborative Filtering via Gaussian Probabilistic Latent Semantic Analysis, SIGIR 2003. |
| LDCC | Wang et al., Latent Dirichlet Bayesian Co-Clustering, Machine Learning and Knowledge Discovery in Databases, 2009. |
| NMF | Seung and Lee, Algorithms for Non-Negative Matrix Factorization, NIPS 2001. |
| PD | Pennock et al., Collaborative Filtering by Personality Diagnosis: A Hybrid Memory- and Model-based Approach, UAI 2000. |
| PMF | Salakhutdinov and Mnih, Probabilistic Matrix Factorization, NIPS 2008. |
| RegSVD | Arkadiusz Paterek, Improving Regularized Singular Value Decomposition Collaborative Filtering, KDD Cup and Workshop 2007. |
| RfRec | Gedikli et al., RF-Rec: Fast and Accurate Computation of Recommendations based on Rating Frequencies, IEEE CEC, 2011. |
| RSTE | Ma et al., Learning to Recommend with Social Trust Ensemble, SIGIR 2009. |
| SlopeOne | Lemire and Maclachlan, Slope One Predictors for Online Rating-Based Collaborative Filtering, SDM 2005. |
| SocialMF | Jamali and Ester, A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks, RecSys 2010. |
| SoRec | Ma et al., SoRec: Social Recommendation Using Probabilistic Matrix Factorization, SIGIR 2008. |
| SoReg | Ma et al., Recommender systems with social regularization, WSDM 2011. |
| SVD++ | Koren, Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model, KDD 2008. |
| timeSVD++ | Koren, Collaborative Filtering with Temporal Dynamics, KDD 2009. |
| TrustMF | Yang et al., Social Collaborative Filtering by Trust, IJCAI 2013. |
| TrustSVD | Guo et al., TrustSVD: Collaborative Filtering with Both the Explicit and Implicit Influence of User Trust and of Item Ratings, AAAI 2015. |
| URP | Benjamin Marlin, Modeling user rating profiles for collaborative filtering, NIPS 2003. Nicola Barbieri, Regularized gibbs sampling for user profiling with soft constraints, ASONAM 2011. |
| Item Ranking | References |
|---|---|
| AR | Kim and Kim, A Recommendation Algorithm Using Multi-Level Association Rules, WI 2003. |
| AoBPR | Rendle and Freudenthaler, Improving pairwise learning for item recommendation from implicit feedback, WSDM 2014. |
| BPR | Rendle et al., BPR: Bayesian Personalized Ranking from Implicit Feedback, UAI 2009. |
| CLiMF | Shi et al., CLiMF: Learning to Maximize Reciprocal Rank with Collaborative Less-is-More Filtering, RecSys 2012. |
| FISMrmse/FISMauc | Kabbur et al., FISM: Factored Item Similarity Models for Top-N Recommender Systems, KDD 2013. |
| GBPR | Pan and Chen, GBPR: Group Preference Based Bayesian Personalized Ranking for One-Class Collaborative Filtering, IJCAI 2013. |
| Hybrid | Zhou et al., Solving the Apparent Diversity-Accuracy Dilemma of Recommender Systems, NAS 2010. |
| LDA | Tom Griffiths, Gibbs sampling in the generative model of Latent Dirichlet Allocation, 2002. |
| LRMF | Shi et al., List-wise learning to rank with matrix factorization for collaborative filtering, RecSys 2010. |
| PRankD | Neil Hurley, Personalised ranking with diversity, RecSys 2013. |
| RankALS | Takacs and Tikk, Alternating Least Square for Personalized Ranking, RecSys 2012. |
| RankSGD | Jahrer and Toscher, Collaborative Filtering Ensemble for Ranking, JMLR, 2012 (KDD Cup 2011 Track 2). |
| SBPR | Zhao et al., Leveraing Social Connections to Improve Personalized Ranking for Collaborative Filtering, CIKM 2014 |
| SLIM | Ning and Karypis, SLIM: Sparse Linear Methods for Top-N Recommender Systems, ICDM 2011. |
| WBPR | Gantner et al., Bayesian Personalized Ranking for Non-Uniformly Sampled Items, JMLR, 2012. |
| WRMF | Hu et al., Collaborative filtering for implicit feedback datasets, ICDM 2008. Pan et al., One-class Collaborative Filtering, ICDM 2008. |
| Both Tasks | References |
|---|---|
| UserKNN | |
| ItemKNN | |
| BHfree | Barbieri et al., Balancing Prediction and Recommendation Accuracy: Hierarchical Latent Factors for Preference Data, SDM 2012. |
| BUCM | Barbieri et al., Modeling Item Selection and Relevance for Accurate Recommendations: a Bayesian Approach, RecSys 2011. |
How to Run LibRec
- 1. Check out the source code with git clone https://github.com/guoguibing/librec.git
- 2. Run Eclilpse, and select "File > Import > General > Existing Projects into Workspace".
- 3. Select "Select root directory: " and browse to the directory where your unzipped source code is stored.
- 4. Press "Finish", and the project is imported.
- 1. Config a recommender by setting librec.conf
- 2. Run the runnable .jar package (make sure the java version is 1.7 or higher)
> java -jar librec.jar
Since librec-v1.2, you can specify alternative configuration file:> java -jar librec.jar -c configFile1.conf [configFile2.conf ...]
- Rating prediction: MAE, RMSE, NMAE, rMAE, rRMSE, MPE
- Item recommendation: Precision@5, Precision@10, Recall@5, Recall@10, AUC, MAP, NDCG, MRR
> java -jar librec.jar [arguments]
| Argument | Example | Since | Description |
|---|---|---|---|
| -c confFile1 [configFile2 ...] | -c myConfig.conf | 1.2 | Set the alternative (multiple) configuration file(s); otherwise default config file ("librec.conf") will be used. |
| -v | -v | 1.2 | Print out the version number. |
| --version | --version | 1.2 | Print out the detailed version information: version number, copyright, LibRec discription. |
| --dataset-spec | --dataset-spec | 1.2 | Print out the detailed specifications of datasets specified by your config file including training/testing/social datasets. |
| --dataset-split -r ratio -target u, i, r --by-date | --dataset-split -r 0.8 |
1.3 | Split the input data set ("dataset.training") into: training, and test sub sets. These subsets are stored in the folder "split" under the same directory of the input data set. |
- 1. Download the latest release zip file and unzip it to a local directory.
- 2. Run command or terminal and use "cd" to locate the library directory.
- 3. Run the LibRec library by: java -jar librec.jar
- 4. An example is illustrated in Figure 2 (with LibRec-1.3). The outputs (with orders) are: algorithm name, performance (MAE, RMSE, NMAE, rMAE, rRMSE, MPE), recommender options (learning rate, reg.user, reg.item, num.factors, num.max.iter, bold.driver), execution time (training time and testing time).

Figure 2. A LibRec example of running BiasedMF on the FilmTrust dataset
public void main(String[] args) throws Exception {
// config logger
Logs.config("log4j.xml", true);
// config recommender
String configFile = "librec.conf";
// run algorithm
LibRec librec = new LibRec();
librec.setConfigFiles(configFile);
librec.execute(args);
}
- The following demo is based on a pre-release version of LibRec-1.3. The demo content is included in the folderdemo.
Config Recommender: librec.conf
| Entry | Example | Since | Description |
|---|---|---|---|
| dataset.ratings.wins dataset.ratings.lins |
D:\\MovieLens\\100K.txt /home/user/ratings.txt |
1.0 | Set the path to input dataset: "*.wins" for Windows, and "*.lins" for Linux and Unix. It is convenient if you need to frequently switch among different platforms. If not, you can use "dataset.ratings" for short. Format: each row separated by empty, tab or comma symbol. |
| dataset.social.wins dataset.social.lins |
D:\\Epinions\\trust.txt /home/user/trust.txt |
1.0 | Set the path to social dataset. Put "-1" to disable it. |
| ratings.setup | -columns 0 1 2 3 -threshold -1 | 1.3 | -columns: (user, item, [rating, [timestamp]]) columns of rating data are used; -threshold: to convert rating values to binary ones --time-unit DAYS, HOURS, MICROSECONDS, MILLISECONDS, MINUTES, NANOSECONDS, [SECONDS]: time unit of timestamps --headline: to skip the first head line when reading data --as-tensor: to read all columns as a tensor |
| recommender | RegSVD/SVD++/PMF/etc. | 1.0 | Set the recommender to use. Available options include: Baselines: GlobalAvg, UserAvg, ItemAvg, UserCluster, ItemCluster, Random, Constant, MostPop; Extensions: NMF, SlopeOne, Hybrid, PD, AR, PRankD, External; Algorithms: check out the advanced algorithms implemented |
| evaluation.setup | cv -k 5 -p on -v 0.1 -o on | 1.3 | Main option: test-set; cv; leave-one-out; given-n; given-ratio; test-set -f path/to/test/file; cv -k kfold (default 5); -p on (parallel execution, default), off (singleton, fold-by-fold); leave-one-out -t threads (number of threads, used only for target r) -target u, i, r (r by dafault) [--by-date] given-n -N number (default 20) -target u, i [--by-date]; given-ratio -r ratio (default 0.8) -target u, i, r [--by-date] -target u, i, r: preserve a ratio of ratings relative to users (u), items (i) or ratings (r); --by-date: sort ratings by timestamps Commonly optional settings include: -v ratio of validation data (derived from training data, default 0) -rand-seed N: set the random seed, if not set, system time will be used; --test-view all, cold-start, trust-degree min max (default all); --early-stop loss, RMSE, MAE, etc: set the criterion for early stop. Note that early-stop may not produce the best performance. |
| item.ranking | off -topN -1 -ignore -1 | 1.3 |
Main option: whether to do item ranking -topN: the length of the recommendation list for item recommendation, default -1 for full list; -ignore: the number of the most popular items to ignore; -diverse: whether to use diversity measures |
| output.setup | on -dir ./Results/ -verbose on | 1.3 | Main option: whether to output recommendation results -dir path: the directory path of output results; -verbose on, off: whether to print out intermediate results; --save-model: whether to save recommendation model; --fold-data: whether to print out traing and test data; --measures-only: whether to print other information except measurements; --to-clipboard: copy results to clipboard, useful for a single run; --to-file filePath: collect results to a specific file, useful for multiple runs, especifially if not all at once. |
| guava.cache.spec | maximumSize=200 | 1.2 | Set the Guava cache specificaiton, see more options |
| email.setup | on/off -host smtp.gmail.com |
1.3 | main option: if email notification is enabled; -host: the email server; -port: the port of the email server -user: the user name of your email account; -password: the password of your email account; -auth true/false: whether the email server requires authentification; -to: the email address to which you want to send notification; |
| num.factors | 5/10/20/number | 1.0 | Set the number of latent factors |
| num.max.iter | 100/200/number | 1.0 | Set the maximum number of iterations for iterative recommendation algorithms. |
| learn.rate | 0.01 -max -1 -bold-driver | 1.3 | Main option: initial learning rate for iterative recommendation algorithms; -max: maximum learning rate (default -1); -moment value; -bold-driver: update by bold driver; -decay ratio: update by constantly decaying; |
| reg.lambda | 0.1 -u 0.01 -i 0.01 -b 0.01 -s 0.01 | 1.3 | main option: default value if specific parameter is not specified; -u: user regularizaiton; -i: item regularization; -b: bias regularizaiton; -s: social regularization |
| pgm.setup | -alpha 2 -beta 0.5 -burn-in 1400 -sample-lag 100 -interval 100 |
1.3 | General setup for probabilistic graphic models: -alpha: the hyperparameter for user-topic distritubion; -beta: the hyperparameter of topic-item distribution; -burn-in: the number of iterations for the burn-in period; -sample-lag: the number of iterations for the sample lag -interval: the interval to print iterative progress if verbose is on |
| similarity | pcc/cos/msd | 1.0 | Set the similarity method to use. Options: PCC, COS, MSD, CPC, exJaccard; |
| num.shrinkage | 25/number | 1.0 | Set the shrinkage parameter to devalue similarity value. -1: to disable simialrity shrinkage. |
| num.neighbors | 60/number | 1.0 | Set the number of neighbors used for KNN-based algorithms such as UserKNN, ItemKNN. |
| AoBPR | -lambda 0.3 | 1.3 | lambda: the ratio of negative examples during sampling |
| BHfree | -k 30 -l 10 -gamma 0.2 -sigma 0.05 | 1.3 | -k/l: number of user/item topics; -gamma/sigma: initial hyperparams for ratings and items. |
| BUCM | -gamma 0.5 | 1.3 | gamma: the initial hyperparameter value for rating probability distributions |
| FISM | -rho 10 -alpha 0.5 | 1.3 | rho: the ratio of sampling negative training examples relative to positive ones; alpha: the weight parameter to the number of items rated by a user. |
| GBPR | -rho 0.6 -gSize 5 | 1.3 | rho: the importance of group preference; gSize: the size of group users, usually 3/4 will be good. |
| GPLSA | -q 5 -b 0.4 | 1.3 | q: the smoothing weight; -b: tempered EM scale parameter. |
| Hybrid | -lambda 0.5 | 1.3 | lambda: the parameter to combine both HeatS and ProbS. |
| LDCC | -ku 20 -kv 10 -au 1 -av 1 -beta 1 | 1.3 | -ku: number of user clusters; -kv: number of item clusters; -au/av/beta: Dirichlet hyperparam for users/items/ratings; |
| PD | -sigma 2.5 | 1.3 | sigma: the prior Gaussian standard deviation. |
| PRankD | -alpha 20 | 1.3 | alpha: the parameter to obtain a greater spread of diversity values. |
| RSTE | -alpha 0.4 | 1.3 | alpha: the importance of user-item (partial) prediction for the overall prediction. |
| RankALS | -sw on/off | 1.3 | sw: whether the supporting weight is enabled. |
| SLIM | -l1 1 -l2 5 | 1.3 | l1/l2: set the l1/l2 regularizaiton parameter value. |
| SoRec | -c 1 -z 0.001 | 1.3 | c: the importance of social regularization; z: the regularization parameter for social users. |
| SoReg | -beta 0.01 | 1.3 | beta: the importance of social regularization. |
| timeSVD++ | -beta 0.04 -bins 30 | 1.3 | beta: set the value of time decay factor; bins: the number of bins for all the items. |
| TrustMF | -m Tr/Te/T | 1.3 | m: the specific model to use; Tr: TrusterMF; Te: TrusteeMF; T: TrustMF. |
| WRMF | -alpha 2.0 | 1.3 | alpha: the parameter to convert from rating value to rating confidence. |
| dataset.testing.wins dataset.testing.lins |
test.txt | 1.0-1.2 | Set the path to testing dataset. Put "-1" to disable it. If specified, algorithm will be tested using this data file. Otherwise algorithm will be tested base on ratio or kfold cross-validation of training set. |
| val.binary.threshold | -1/0/float | 1.2-1.2 | For item ranking/recommendation: set the threshold (must be non-negative) to convert real-valued ratings to binary ones (equal or greater than threshold, then value 1; otherwise value 0). Note that not all item ranking models require binary ratings. Put "-1" to disable it. |
| is.prediction.out | on/off | 1.2-1.2 | Set whether to output rating predictions to files (located under the folder "Results") |
| rating.pred.view | all/cold-start | 1.1-1.2 | Set the testing view if rating prediction is used. Supported views: all/cold-start |
| is.cross.validation | on/off | 1.0-1.2 | Set whether to enable cross validation for testing. |
| is.parallel.folds | on/off | 1.0-1.2 | Set whether to run kfold cross validation parallely. Off: kfolds will be executed one thread after another, useful if memeory is a critical issue. |
| num.kfold | 5/number | 1.0-1.2 | Set the number of folds to use. |
| val.ratio | 0.8/float | 1.0-1.2 | Set the ratio of all data as the training set. If kfold is off, single ratio will be executed, useful for 0.8 training, 0.2 testing. (Note: for consistency's sake, since v1.1 onwards, the ratio means the training ratio while in v1.0 the ratio means the testing ratio) |
| num.given.n | 5/10/number | 1.1-1.2 | Set the number of given ratings for each user that will be preserved as the training set, and the rest are used for testing if val.ratio<0, a.k.a, Given N. |
| val.given.ratio | 0.8/float | 1.1-1.2 | Set the ratio of given ratings for each user that will be preserved as the training set, and the rest as the testing set if num.given.n<0, i.e., Given Ratio. |
| val.reg.user | 0.2/float | 1.0-1.2 | Set the reguralization for users. |
| val.reg.item | 0.2/float | 1.0-1.2 | Set the regulralization for items. |
| val.reg.bias | 0.01/float | 1.2-1.2 | Set the regularization for user/item biases |
| val.reg.social | 0.2/1/5/float | 1.0-1.2 | Set the regularization for social information. It is useful for social recommenders. |
| is.bold.driver | on/off | 1.0-1.2 | Set whether to use "bold driver" mode to udpate learning rate. On: increase 5% if loss value decreases; otherwise decreasing to 50%. |
| is.undo.change | on/off | 1.0-1.2 | Set whether to undo last changes if bold driver is on and loss value increases. |
| val.decay.rate | 0.9/-1/float | 1.0-1.2 | Set the ratio to decay the learning rate after each iteration. It is only used when bold driver is off. -1: to disable it and use constant learning rate. |
| val.learn.rate | 0.01/float | 1.0-1.2 | Set the learning rate for iterative recommendation algorithms. -1: to disable it. |
| val.momentum | 0.8/float | 1.0-1.2 | Set the momementum for iterative recommendation algorithms. Current it is only used in PMF method. |
| max.learn.rate | 0.05/float | 1.1-1.2 | Set the maximum learning rate if learning rate is updatable. -1: to disable it. |
| is.ranking.pred | on/off | 1.0-1.2 | Set whether to do item recommendation, i.e., item ranking; Off: do rating prediction instead. |
| is.diverse.used | on/off | 1.0-1.2 | Set whether diversity measures are used for item recommendation. |
| num.reclist.len | number/-1 | 1.0-1.2 | Set whether to use diversity measures |
| num.ignore.items | -1/number | 1.0-1.2 | Set the number of the most popular items ignored for item recommendation. |
| is.email.notify | on/off | 1.0-1.2 | Set whether to send an email to notify you if your execution is finished. |
| mail.smtp.host | smtp.gmail.com | 1.2-1.2 | Set the email server. |
| mail.smtp.port | 465 | 1.2-1.2 | Set the port of the email server. |
| mail.smtp.auth | true/false | 1.2-1.2 | Whether the email server requires authentification. |
| mail.smtp.user | user name | 1.2-1.2 | Set the user name of your email account. |
| mail.smtp.password | password | 1.2-1.2 | Set the password of your email account. |
| mail.to | user@gmail.com | 1.2-1.2 | Set the email address that you want to send notification to. It replaced the prviouse item "notify.email.to". |
| is.verbose | on/off | 1.0-1.2 | Set whether to print out detailed debug information. |
| num.rand.seed | 1/-1/integers | 1.0-1.2 | Set the seed of random. -1: use current system time to initial the random generator. |
Development
| Type | Naming | Example |
|---|---|---|
| String | [var.name] | dataset=epinions |
| Boolean (on/off) | is.[var.name] | is.verbose=on/off |
| Integer/Number | num.[var.name] | num.kfold=5 |
| Real float | val.[var.name] | val.ratio=0.2 |
| Maximum (Minimum) value | max.[var.name] min.[var.name] |
max.ratio=1.0 min.ratio=0.1 |
| Range/Set (multiple values) | val.[var.name] | val.reg=0.5,0.6,0.7,0.8 works the same as val.reg=0.5..0.1..0.8 val.reg=0.0001,0.001,0.01,0.1,1 can be shortened as val.reg=0.0001**10**1 |
| IO path Note: use [var.name] as key in your program |
[var.name] in general, for simplicity |
ratings=D:\\ratings.txt |
| Remark: Class Configer is used to read desired variable values. | ||
- 1. Creating a new class by extending a proper interface.
- 2. Initialize your model by overriding the method initModel(), if necessary.
- 3. Building your model by overriding the method buildModel(), if necessary.
- 4. Evaluate your model by overriding the method predict(int u, int j, boolean bounded) (for rating prediction) or ranking(int u, int j) (for item recommendation), if necessary.
- 5. Register your recommender in the method getRecommender(SparseMatrix[] data, int fold) of the main class LibRec.java.